Hi, i am currently developing a chat bot for movie ticket booking.
I want to use a lookup table for “language” entity. But my chatbot is not predicting the languages which are there in lookup table, but it is working fine with the training examples.
I think my config.yml is not correct. I tried so many pipeline configurations, but none of them were working. I also tried looking in this blog but it is a outdated blog, the configurations now we have were changed compared to it.
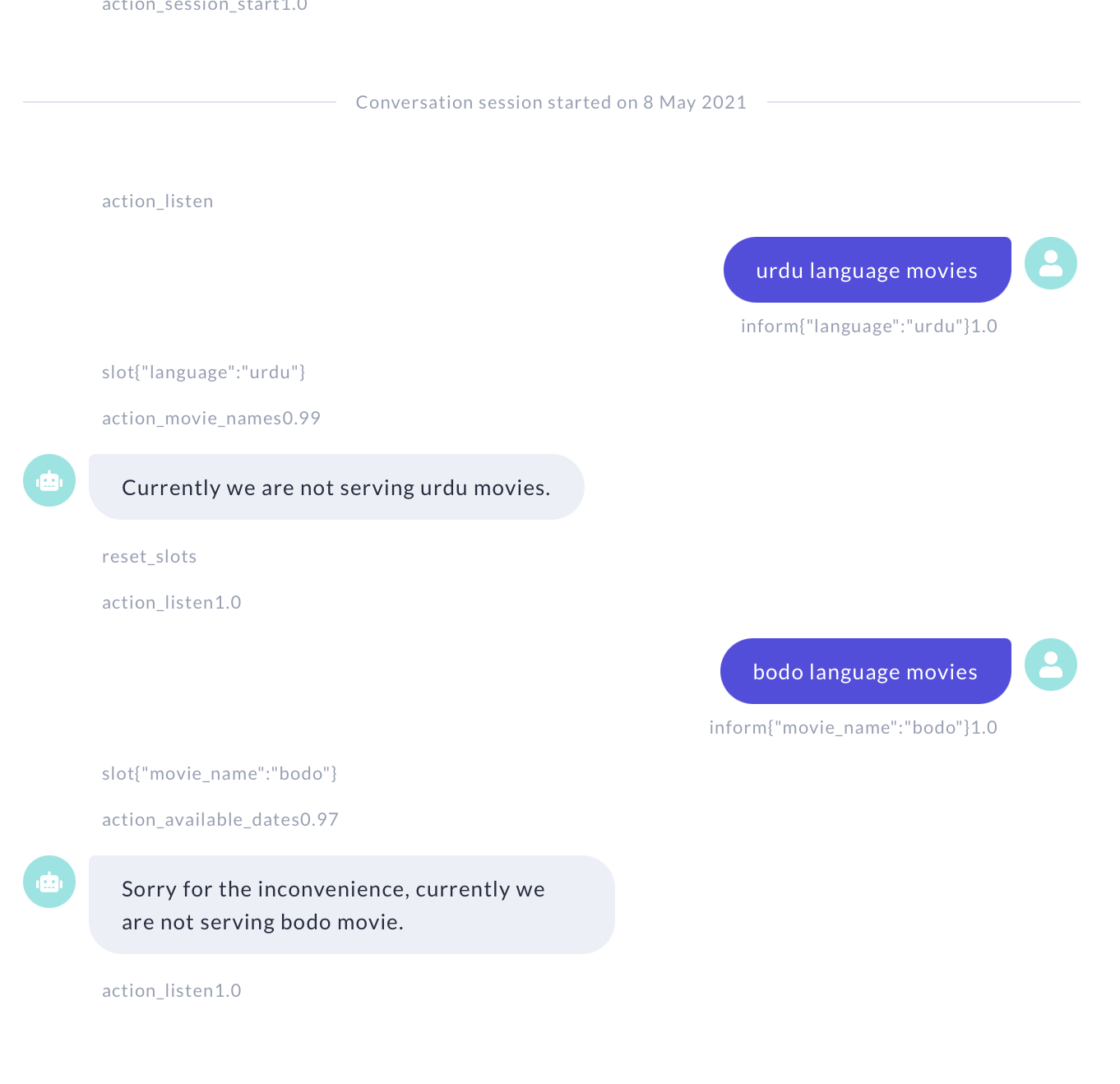
In the first message it is correctly picking the “language” entity.
But in the second message it is picking “bodo” language as a movie_name.
Eventhough i didn’t added urdu in my training data it is working fine, but “bodo” is not working fine.
I don’t even understand whether my lookup table is working or not.
# Insert normal .txt/.csv path here
file = open(r"C:\Users\User\Desktop\Cities in the World.csv", "r")
# Splits each row
lines = file.read().splitlines()
n = 0
# Insert target output path here
file2 = open(r"C:\Users\User\Desktop\cities.yml", "w")
# Writes the headers(?), remember to change the lookup name
file2.write("version: \"2.0\"\nnlu:\n - lookup: city \n examples: |\n")
# Adds indent and dash to each line
for line in lines:
file2.write(" - " + str(line) + "\n")
# Closes the files
file.close()
file2.close()
Yeah it is working fine now, once again thank you so much I’ve been searching for this for a few days
but couldn’t find any documentation about this, finally made it working.
I am also trying to implement fuzzyword matching, do you have any idea about this or any documentation regrading this topic.
@fkoerner I already watched the session, she implemented it in a form to check the user messages with some mistakes, but i want to implement it as a custom component which will have to pickup entites with misspells
@saimanoj2826 you can look at the RegexEntityExtractor for inspiration. Basically, a FuzzyEntityExtractor can work similarly, except that this line will need to allow for fuzzy matches. Does that help?
I was just trying to say that the custom implementation would look very similar to the RegexEntityExtractor, so you could use that as a starting point. Does that make sense?
@fkoerner i am using rasa 2.0. Can you please tell me the exact order of the pipeline in config.yml file.This is what i am using but its not picking up the entities
@saimanoj2826 I am also facing same issue, can you please help me with your config pipeline components.
I also have same pipeline components as yours, here I have posted my issue.
Hi there, how come you also have the RegexFeaturizer in your pipeline? Further, what do you mean it’s not picking up the entities? Did you add one or two of the entities to your NLU examples?
@fkoerner so suppose I have a list of 20 colors… For two colors: red and black I have training examples in my nlu file… Rest of the colors I have added in lookup table… With the above pipeline it’s picking up red and black only because I have training examples for them in my nlu file but not the ones I have included in my lookup table