This is going to be long… but I hope this helps.
First of all, I’m assuming you don’t have anything in your phrases that should be treated as an entity. If you have examples like this:
## intent: order
- I want a loaf of bread
- I want a cake
- I want a glass of water
- I want some butter
- I want some sugar
I would change it to entities, and the variations would be “I want xxx”, “I’d like yyy”, “Could you get me zzz”, “Can I order aaaa”, with the xxx, yyy, zzz, aaa etc… all being treated as an entity. I don’t need 4x4=16 examples. I can get by with 4. Like I mentioned, there are only so many ways you can order something. You can order several different items, but the intent is the same.
On that foot, I haven’t seen any blog posts that say “you need X examples”, but a good place to start is to look at the demo files here: rasa/examples at master · RasaHQ/rasa · GitHub
Explaining a little about accuracy… by 95%, I meant that our chatbot responds correctly to 95% of the test phrases we throw at it (the other 5% triggers a fallback, and is acceptable to our customer). The average accuracy over all the sample phrases is around 88%.
You don’t need to have 100% accuracy on each intent. We use a threshold of 0.6. So anything under 0.6 drops us into our fallback action. We started of at .8, then tested with 0.7 and finally with 0.6. Yours is set at 0.3, which I feel is a bit low, and you’d probably get some incorrect classifications there which should trigger a fallback, instead of wrong classification.
The top ten intents for a test phrase thrown at Rasa can be found using API functions (check out the parse function here: HTTP API). This gives you a JSON document with a ranking of the top 10 intent classifications.The sum of all intents gives you 100%, correct? Testing all the intents, I found that if you have an accuracy of 0.6, the second in the classification ranking is around .2, and the third around .1. An accuracy of 90% or higher will give an accuracy for second and third around 1%, so they are a world away. If you have a confusing phrase, at threshold 0.3, you can get more than one above this, and it’s easier to get the wrong intent.
After you have some idea of the ranking, you can see which are the closest intents, and what examples need tweaking.
Like I mentioned, without taking a look at an intent to see what your doing with your examples, my diagnosis is limited to my experience. But, at the moment it looks like you’re basically trying to brute-force the chatbot, assuming that a ton of examples will give you a good model, and just adding them to your NLU, making it work harder. And don’t forget: having a model with 200-300 examples to test is also more compute-intensive to classify!
I don’t think you need so many, and I would backup your training data, take 50 intents, leave only say 30 significant examples of each one, and train this, and make up a report showing where there’s confusion (see below). Figure out what is causing the confusion and tweak the examples, then add another 50 intents, and repeat over again, and again until you have all intents back in your training data. This will be a lot of work, but you’ll end up with a better model.
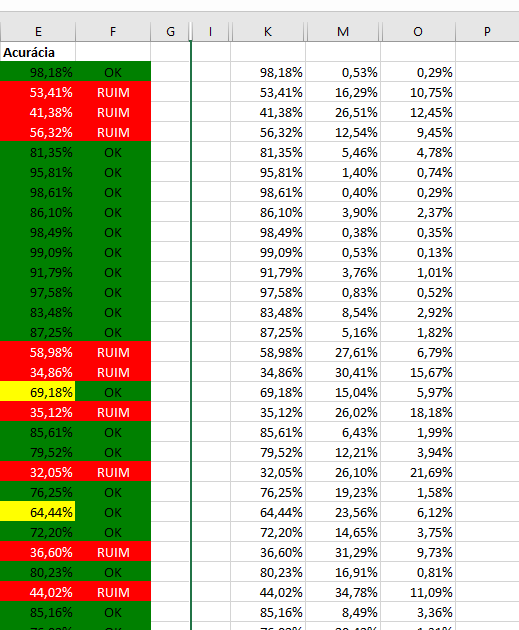
Here’s a bit of our spreadsheet (I hope it’s ok to link to an external image here), so you can see what I analyze. I had to hide to names of the intents because of confidentiality issues with our customer, but each line is a test phrase thrown at Rasa. Column E is the accuracy. Column F is a go/no go (OK/RUIM). If it’s the correct intent and over .7, I mark it in green. If it’s over .6 and less than .7, I mark it yellow as it could slip under the threshold if I’m careless with examples from other intents. Under .6 it’s marked in red. Columns K, M and O are the top three intent classifications for the test phrase (hidden columns J, L and N have the intent name so I know where the problem is).
If I see a phrase that needs improving, I look at all the examples of the intent that’s causing confusion, and what phrases are too similar. I then add a couple of examples that emphasize specific words that can differentiate the two intents. A single example can impact on all the intents (even if it’s by 0.00001%). That’s why I mark some in yellow. They’re the one’s I need to keep an eye on. If an intent is 90%, then it’s unlikely that I mess it up unless the exact example is in another intent.
Sometimes, looking at the expected response from the chatbot, we propose merging two intents with our customer, and if we can do that, just add the examples from one to another. (we have a few intents with 30 examples, but none over that).
Why don’t I use the rasa test report? Because it only shows wrongly classified intents, but not if it’s the correct intent below threshold, and I can’t tell if the second place in the ranking is nearly at the same accuracy or irrelevant.
Cheers
 . You don’t need to keep repeating the same phrase over and over again to increase accuracy. Can you post one of the intents with it’s sample phrases to have a look at?
. You don’t need to keep repeating the same phrase over and over again to increase accuracy. Can you post one of the intents with it’s sample phrases to have a look at?
{kind=link}