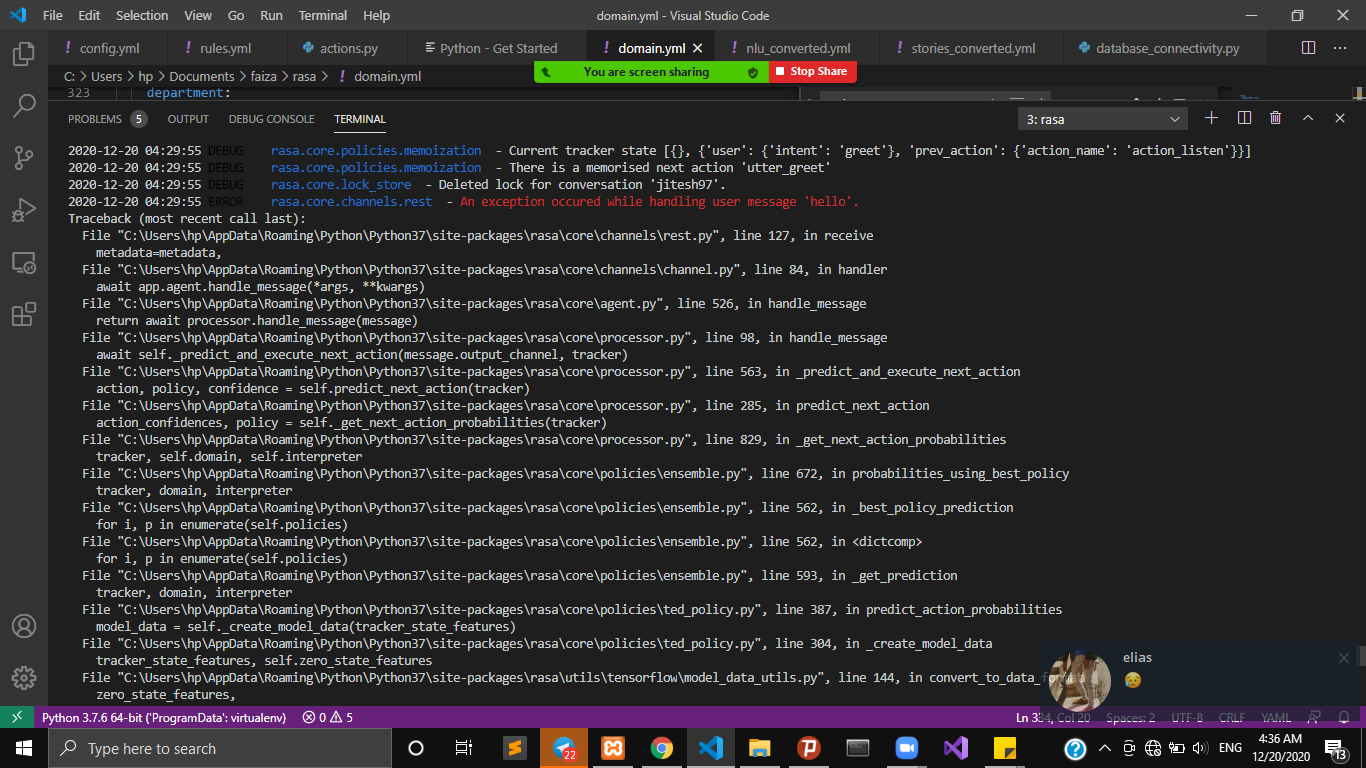
while filling a form if we have one entity that has regex ,what would the form will look like, from_text or from_entity inorder to catch the regex? i have regex for height which is /d{1}./d{2}cm|CM and while filling a form i tried both from_entity and from_text to catch user input what ever number they enter as long as it looks like this(1.76cm,1.23cm …etc)…
from_entity should be correct. Is this not working for you?
@fkoerner From entity works but since both diet classifier and regexentityextracter extractes the entity it becomes a list…and how should I get one of them inorder to store it to database or do a validation


This is a known problem, see the issue for it here.
For now, can you just index into the list and process the phone number one-by-one (phone_no[0]).
@fkoerner…yes I try to indenx over it…but for string it works but for number I have to do like this phone_no[2:13] or else it will only takes anything found at index 0 which is a single this like might be just [ this or other
@fkoerner…I go to the github link u send but the issue is filed and still no one has answerd there yet
@fkoerner… can you please explain me here shortly on what kind of algorithms is used to build the rasa pipelines and policies …and when installing rasa we have a requirement.txt that needed to be installed so why do we need them or why rasa need them?
yes I try to indenx over it…but for string it works but for number I have to do like this phone_no[2:13] or else it will only takes anything found at index 0 which is a single this like might be just [ this or other
This sounds like sometimes it’s a string and sometimes it’s a list. You can check which one with something like this:
if isinstance(phone_no, list):
phone_no = phone_no[0]
I go to the github link u send but the issue is filed and still no one has answerd there yet
Yes that’s true! I meant to share it to show that we are aware and maybe will do something about it if we think that will improve the user experience. Sorry for the confusion.
@fkoerner… can you please explain me here shortly on what kind of algorithms is used to build the rasa pipelines and policies …and when installing rasa we have a requirement.txt that needed to be installed so why do we need them or why rasa need them?
Depends which pipeline and policy you’re referring to! If you’d like to know about the architectures and policies we designed there’s information about TED here and you can read more about DIET here. There are pipeline components and policies for lots of different use cases. You can read more about them here and here. If something’s unclear, you can also ask a question.
The requirements.txt file lists python packages that are needed for rasa. There are different packages for different purposes. You can ask about a specific one if you’d like. Including a requirements.txt file ensures that you get the right packages with the right versions when you install with pip. This is standard practice (outside of rasa, as well), which you can read more about here
@fkoerner…these are my pipelines and policies
- name: "DucklingEntityExtractor"
url: "http://localhost:8000"
dimensions: ["time", "email"]
# timezone: "Ethiopia/addis abeba"
timeout: 3
- name: WhitespaceTokenizer
- name: RegexFeaturizer
- name: RegexEntityExtractor
- name: LexicalSyntacticFeaturizer
- name: CountVectorsFeaturizer
- name: CountVectorsFeaturizer
analyzer: "char_wb"
min_ngram: 1
max_ngram: 4
#- name: CRFEntityExtractor
- name: DIETClassifier
epochs: 100
- name: EntitySynonymMapper
- name: ResponseSelector
epochs: 100
#retrieval_intent: faq
- name: FallbackClassifier
threshold: 0.7 ```
```policies:
- name: MemoizationPolicy
- name: TEDPolicy
max_history: 8
epochs: 200
#- name: "coco_rasa.CoCoContextPolicy"
- name: RulePolicy```Which part do you have questions about in particular?
@fkoerner…my question is …what kind of nlp model is used in rasa??..among the pipelines which part is nlp model and which part is machine learning algorithms…the term NLP model and the term machine learning gets confused to me here…among the pipelines can you tell me based on what nlp models that these algorithms are built…short answer no problem please dont link me a docs I have read most of them and it doesn’t illustrate or give me the answer am looking for 
Many NLP models and tools are used in rasa. Virtually every component can be viewed as either an NLP model or tool. NLP (Natural Language Processing) is a broad term, that can apply to anything that facilitates interactions between computers and natural language.
Machine learning is also a broad term that describes models that improve their predictions with data. Some NLP models use machine learning, for example DucklingEntityExtractor was created by machine learning to perform the NLP task of extracting entities.
WhiteSpaceTokenizer does not do any machine learning, but rather splits tokens on whitespace. It is an NLP tool, as it tokenizes natural language text for further processing.
So broadly speaking, virtually all components in the pipeline are NLP components, but not all of them use machine learning.
As an aside, if you feel something is missing from the docs, please make an issue on github.
@fkoerner…thanks a lot …now I got a clear answer between the nlp term and machine learning…so among my pipeline that i have send you which one uses machine learning and which one doesn’t use machine learning ?.. those who uses machine learning ,do we that they use machine learning library or machine learning algorithms??