My team recently tried to migrate to Rasa 2.0. We’ve had several issues with the TED and especially that it doesn’t have the same metrics (t-loss, loss, accuracy) with the ones we got through training in Rasa 1.10.8.
We’ve tried to train TED for various hyperparameter settings (changed dense dimensions, epochs (30-200), batch sizes) but still got mediocre results (Rasa 1.10: 99% accuracy, Rasa 2.0: 84% accuracy).
Also, I would like to point out that theoretically the network would have to overfit. We’ve tried training with 40,100,300 epochs but the accuracy is still the same.
The policy used:
I will attach some snipets from the training procedure.
Thus, I don’t think it’s a hyperparameter tuning problem. Maybe the embedding space is not that large but I’ve tried changing it also.
Is something wrong with the implementation of TED in Rasa 2.0?
PS. We’ve secured a higher accuracy (93.4%) by setting the max_history to 10 or 13 but this exponentially increases the training time. Also, as far as I’m concerned, for shallow conversations (with a depth of 5-7 dialogue turns) this shouldn’t produce better results. Our tests (either automatically from rasa test or from manual shell+actions testing) are usually 5-7 turns.
After some debugging (and after I’ve finally saw that _write_mode_summary is initiated if tensorboard logdir is present in cofig.yml) I’ve noticed some differences.
Are you sure you use the same stories? Because in the link you posted, we found out that there were contradictions and amount of stories recalled by memoization policy changed
Yes I’m almost sure. rasa data validate don’t produce any contradiction and we’ve had automated migration from markdown to yml. Thus, I think it’s highly unlikable for the stories to be changed.
in data fraction is the fraction of next actions that Memoization (or Augmented Memoization) predicted. In the forum, it is stated that Rule Policy and Memoization has a different priority. Thus, when both of them predict something with confidence 1.0, Rule policy is the one that is charged for the prediction and in data fraction falls.
Also, we’ve had several interactive stories appended to solve the problem and it seems that TEDs accuracy increased marginally.
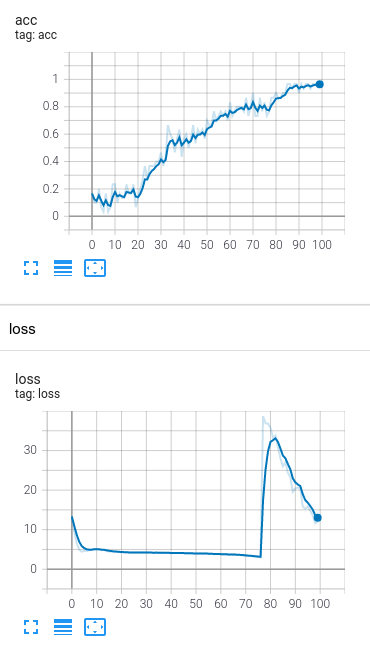
I’ve also noticed that for the init chat bot, in Rasa 1.10.8 TED reaches 98% after the 3rd epoch where as in Rasa 2.0 its vastly different (85.8% after 100 epochs with great loss spikes up and down).
amazing! I’ll prepare the PR. Don’t worry about the loss. We have scale_loss parameter that upscales the loss, so that examples that are hard to learn have stronger signal