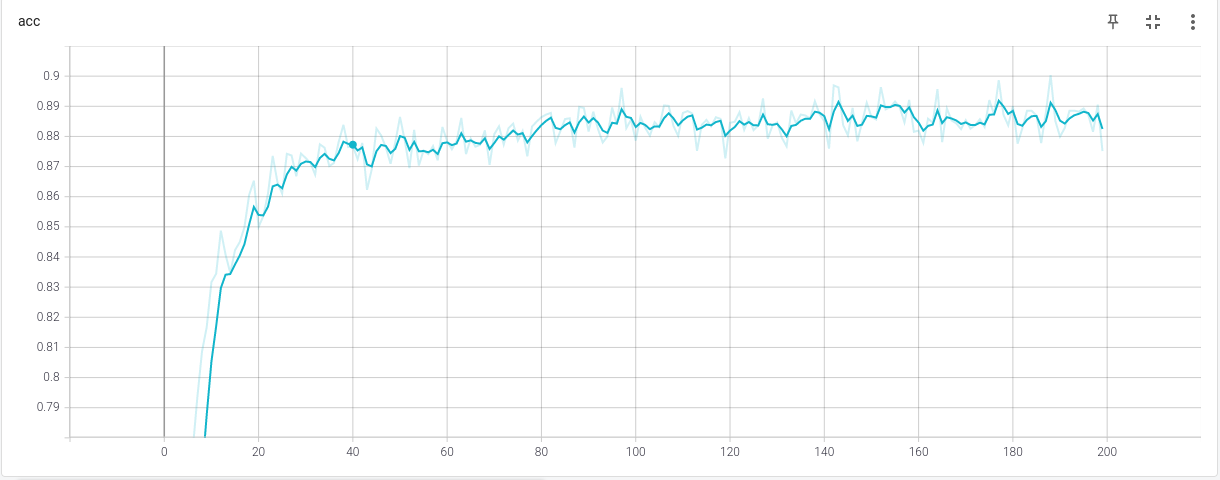
We are migrating to rasa 2.0, and we have observed a rather strange issue. The training stories are the same, and the batch sizes were restored to [8,32], as they are in Rasa 1.10 by default. However training accuracy has fallen significantly (around 10%, or worse after the network starts overfitting). We are talking about a change from ~98% (Rasa 1.10) to ~89% (Rasa 2.0). What’s more, we’ve seen some failures of the bot when testing our bot, which didn’t happen before.
Has anyone else noticed this? Could it be that the accuracy displayed when training Rasa 1.x is not the same value as the one displayed in Rasa 2.0 ? Have there been other changes to the training of the TED model?
70 epochs in both cases. What really bugs me though is that, with Rasa 1.10 we got to 90% accuracy after 10 epochs, while now accuracy is lower than 75% in the first 20 epochs. We are still looking into it, we will update with news if we have any
We don’t see a big difference. Most probably we’re overfitting after some point. We have set evaluation stories to 0, because we have very few stories in general, just 87. However, we will re-train the model with 10 evaluation examples, and post the results here in half an hour. What changes have been introduced to the TED policy? I’ve only seen the default batch size in the changelog.
In order to accommodate big datasets, we change TED input to be sparse and therefore introduced a couple of dense layers similar as in DIET to process it.
How big is your training data? Does it have contradictions?
We have rather few stories, 87. We have no contradictions. Setting dense_dimension: 64 or 128` didn’t help, here are the results for 64. With 128 it was slightly better.
I’m not sure I’m allowed to… Here are some of our stories:sample stories.yml (12.9 KB)
By the way, I’m not sure if it’s because of the difference in the TED models, but some behaviours don’t generalize very well in Rasa 2.0. Also, core fallbacks happen more frequently, especially for unhappy paths.
I can’t think of a fast way to do this. You mean remove all polices but TED and then test manually each story? Or rewriting them as end-to-end test and run with rasa test?
Wow, I didn’t know there was such a command.
results:
2021-01-21 18:06:41 INFO rasa.core.test - Finished collecting predictions.
2021-01-21 18:06:41 INFO rasa.core.test - Evaluation Results on CONVERSATION level:
2021-01-21 18:06:41 INFO rasa.core.test - Correct: 66 / 80
2021-01-21 18:06:41 INFO rasa.core.test - F1-Score: 0.904
2021-01-21 18:06:41 INFO rasa.core.test - Precision: 1.000
2021-01-21 18:06:41 INFO rasa.core.test - Accuracy: 0.825
2021-01-21 18:06:41 INFO rasa.core.test - In-data fraction: 0.832
2021-01-21 18:06:41 INFO rasa.core.test - Stories report saved to results/story_report.json.
2021-01-21 18:06:42 INFO rasa.core.test - Evaluation Results on ACTION level: 2021-01-21 18:06:42 INFO rasa.core.test - Correct: 1240 / 1273
2021-01-21 18:06:42 INFO rasa.core.test - F1-Score: 0.974
2021-01-21 18:06:42 INFO rasa.core.test - Precision: 0.976
2021-01-21 18:06:42 INFO rasa.core.test - Accuracy: 0.974
2021-01-21 18:06:42 INFO rasa.core.test - In-data fraction: 0.832
2021-01-21 18:06:42 INFO rasa.utils.plotting - Confusion matrix, without normalization:
[[ 1 0 0 ... 0 0 0]
[ 0 26 0 ... 0 0 0]
[ 0 0 50 ... 0 0 0]
...
[ 0 0 0 ... 60 0 0]
[ 0 0 0 ... 0 7 0]
[ 0 0 0 ... 0 0 4]]
For some reason, I see that some stories generated by rasa-interactive were not tested.
As for Rasa 1.10:
2021-01-21 18:19:48 INFO rasa.core.test - Finished collecting predictions.
2021-01-21 18:19:48 INFO rasa.core.test - Evaluation Results on CONVERSATION level:
2021-01-21 18:19:48 INFO rasa.core.test - Correct: 68 / 76
2021-01-21 18:19:48 INFO rasa.core.test - F1-Score: 0.944
2021-01-21 18:19:48 INFO rasa.core.test - Precision: 1.000
2021-01-21 18:19:48 INFO rasa.core.test - Accuracy: 0.895
2021-01-21 18:19:48 INFO rasa.core.test - In-data fraction: 0.922
2021-01-21 18:19:48 INFO rasa.core.test - Evaluation Results on ACTION level:
2021-01-21 18:19:48 INFO rasa.core.test - Correct: 1227 / 1238
2021-01-21 18:19:48 INFO rasa.core.test - F1-Score: 0.991
2021-01-21 18:19:48 INFO rasa.core.test - Precision: 0.991
2021-01-21 18:19:48 INFO rasa.core.test - Accuracy: 0.991
2021-01-21 18:19:48 INFO rasa.core.test - In-data fraction: 0.922
2021-01-21 18:19:48 INFO rasa.core.test - Classification report:
Checking results/failed_test_stories I found some interesting story contradictions we had missed (undetected by rasa data validate). The accuracy on CONVERSATION level is close the accuracy shown in the training process.
What is curious though is that we have similar contradictions in rasa 1.10, the reported accuracy in training is 99%, which is the accuracy on ACTION level. Could it be that in Rasa 2, the accuracy displayed in the loading bar is the Conversation Accuracy while in Rasa 1, the accuracy is the Action Accuracy?
yes, memoization policy, just a tool to measure how much data is directly from training data. if not all you training data is in the training data, it means there are contradictions