I am trying to implement an entity extraction model using the CRF extractor. To do so, I have made 2 configurations: one with only sparse features and another one that takes dense features (BERT) as well.
The problem is that I have the exact same results as if the dense features are not being considered at all while I can see it training in the train phase. The same happens when I train it on a different dataset.
What is the bot’s domain? If you have a narrow domain it’s better to go supervised, LMs won’t be doing much difference.
“The problem is that I have the exact same results as if the dense features are not being considered at all while I can see it training in the train phase.”
How did you observe it?
I do not use cross-validation as I want to compare models using the same test dataset.
The exact same mistakes are being made with and without LM.
The bot goal is to fill administrative forms so the entities are quite general like name, surname, age, profession… I do not agree about LM not doing much difference as I can see the difference when using the DIET config as an entity extractor. I don’t know if I can conclue that LM do best when passed through a transformer but I think that it’s quite wierd that I am having the exact same results with CRF.
I’m observing the result using the CRF_entity_extractor report and errors.
Hello @liaeh !
From what I understood (I am not sure if that is really the case), but CRF takes into account only sequence features while the languageModelFeaturizer return both sentence and sequence features.
According to the documentation, the classifier decides wich kind of features to use. As the CRF is a sequence model, it should use sequence features only but yet as the results shows it fails to do that.
What I did, and it seems to be working is that I used the entity extraction of the DIET classifier and put the transformer layer to 0. That way, the configuration is almost the same as the CRFentityExtractor except the forward neural networks between the features and the CRF. As the DIET architecture takes into consideration the language model features, it’s a way to trick the CRF into using them as well.
Hi @imene_tar, thanks for the answer! Your workaround is helpful.
Still, as you say it seems like the documentation is incorrect: CRFEntityExtractor is supposed to include all dense features of len(tokens), which is is not I have opened a GitHub issue about this and linked our forum posts - hopefully it helps with a fix
Yes, but when using DIET as en entity extactor with the exact same tokenizer, the language model is taken into consideration while it’s not the case when using CRF only. (As I stated previously, I think that DIET knows which features to choose that’s what the CRF is working in your case)
The difference is caused by the WhitespaceTokenizer though. I just ran the same configurations but without DIET and there I also seen two difference confusion matrices.
What I meant was that when using the LanguageModelTokenizer with DIET, the model is perfectly working so I don’t understand why it should cause any problem in CRF.
Anyway, I have replaced it with the whitespacetokenizer as you suggested and I still have the exact same result with and without the language model.
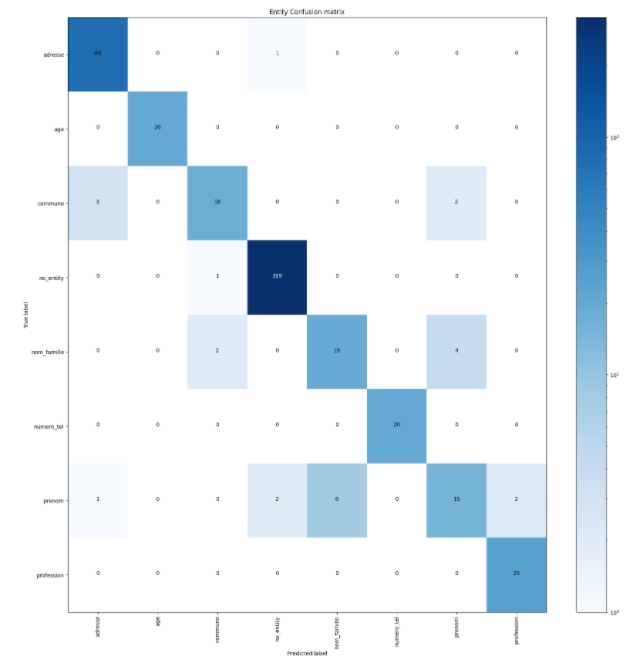
I just ran my two configurations against your data and I can again confirm that the predictions from the CRFEntityExtractor are different. You can explore both the confusion matrix and the configurations by expanding below.
Since the only difference between the two models is the LanguageModelFeaturizer component I must conclude that the CRFEntityExtractor is indeed picking up the features. I also notice that the second configuration is a fair bit slower to run, again indicating that there are features being picked up.
When I train both systems I see a difference in training time.
> time rasa train nlu --config config.yml --fixed-model-name config-base
3.66s user 3.07s system 139% cpu 4.842 total
> time rasa train nlu --config config-lm.yml --fixed-model-name config-lm
24.26s user 3.96s system 244% cpu 11.536 total
When I run the test command I see the same pattern.
> time rasa test nlu --model models/config-base.tar.gz
5.29s user 4.41s system 189% cpu 5.111 total
> time rasa test nlu --model models/config-lm.tar.gz
38.32s user 6.11s system 205% cpu 21.620 total
So there’s definitely a difference between the two configurations just by looking at the time it takes. The reported confusion matrices are the same from both of these test runs because every entity was predicted correctly by the model.
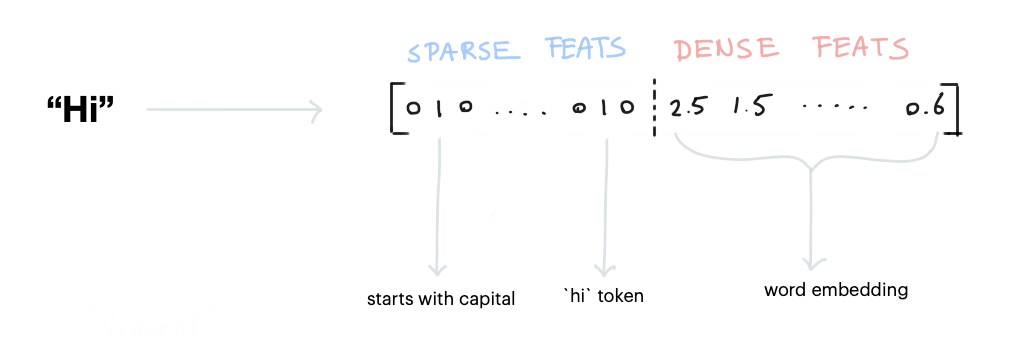
When a token is featurized, it creates both sparse features and dense features. If the sparse features are able to cause a perfect prediction, the model will be able to ignore the dense features. This is possible.
I will investigate further later today though to confirm if I can spot a difference between confidence values.
 I have opened a
I have opened a