You can find a custom naive bayes classifier on the rasa-nlu-examples project.
In terms of a quick overview of our component stack, here’s a quick summary.
Rasa NLU Pipeline
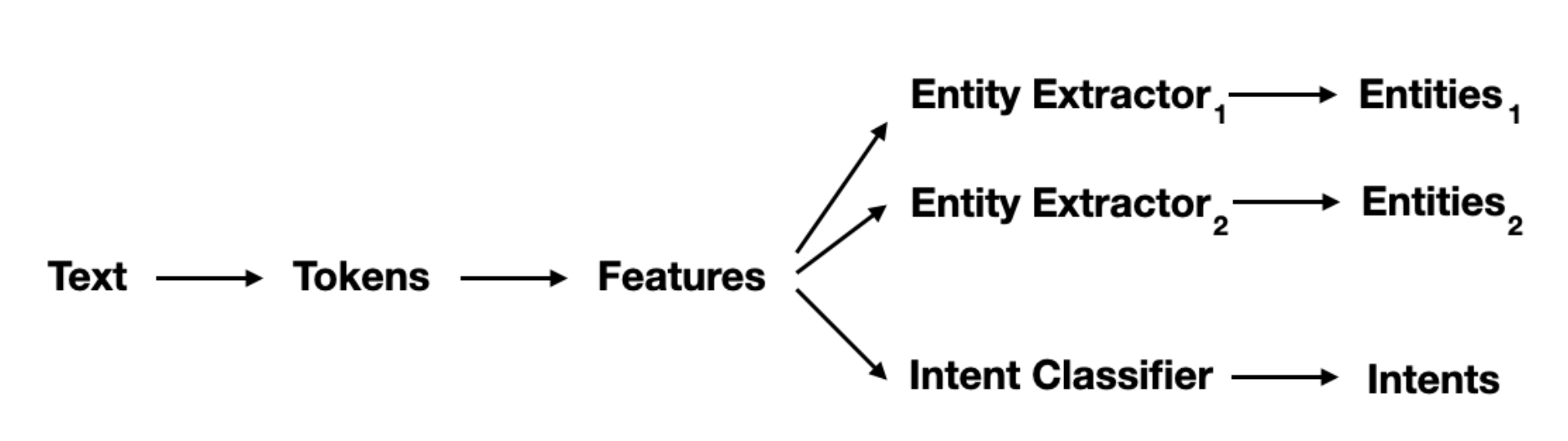
The NLU Pipeline in Rasa concerns itself with detecting intents and entities. It starts with text as input and it keeps parsing until it has entities and intents as output.
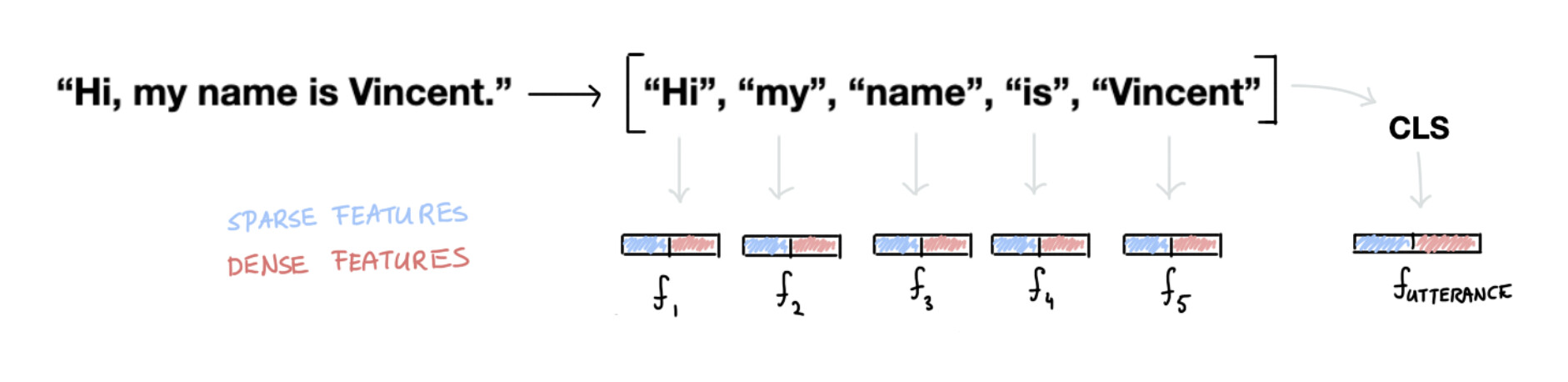
The text is first turned into tokens.
After that, we take the tokens and text and we generate features for each. Some of these features are sparse (countvectors) while others are dense (word embeddings).
Besides features for tokens, we also generate features for the entire utterance. This is sometimes also referred to as the CLS token but we internally call it the sentence feature. The sparse features in this token are a sum of all the sparse features in the tokens. The dense features are either a pooled sum/mean of word vectors (in the case of spaCy) or a contextualised representation of the entire text (in the case of huggingface models).
Finally once we’ve got our features set up we can pass it to a model.
Rasa allows you to bring your own model for intent classification, entity extraction and response selection, however, it’s probably best that you use the DIET model for both intent classification and entity extraction. You can read the paper for more information but you may also enjoy our algorithm whiteboard series on the model.
A Rasa pipeline can have one, and only one, intent detection algorithm. Entity extraction algorithms, on the other hand, can run in parallel. So your diagram could look like this:
Note that each model can decide what to listen to. DIET ignores tokens, but it definitely needs numeric features. Other entity detection methods, like spaCy, might ignore the numeric features entirely and will only look at the text going in.
Message Objects
During this entire pipeline procedure we keep track of an object called Message. It’s like a dictionary. Every time it passes through a component we attach extra information to it. In the beginning it’s just "text" that is attached. But later we will attach "tokens", as well as features and model output. The Printer class that I mentioned earlier does a pretty good job at showing this.
Does this help?
 thanks to you)
thanks to you)