Yep. I totally learned something today. Thanks @Lindafr!
So here’s what I’ve been able to confirm: yes you can add spaCy POS features using the LexicalSyntacticFeaturizer. This was unknown to me before but I can confirm that indeed it adds features. My previous answer was wrong.
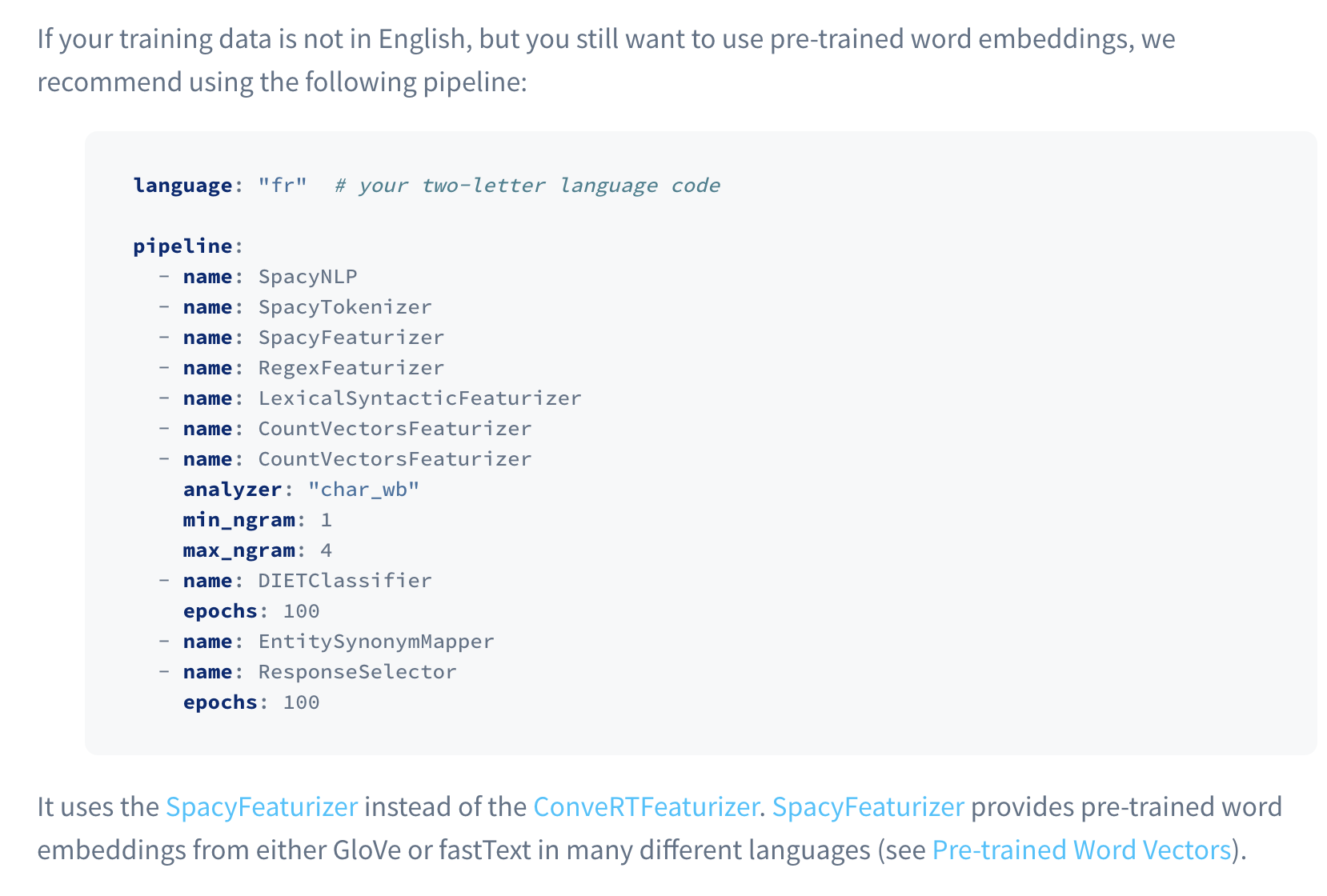
Over on the rasa nlu examples project I’ve made a component called rasa_nlu_examples.meta.Printer. This component allows you to print some extra information from the component pipeline. Here’s two examples of pipelines with that component.
Example 1: No POS
language: en
pipeline:
- name: SpacyNLP
model: "en_core_web_sm"
- name: SpacyTokenizer
- name: rasa_nlu_examples.meta.Printer
alias: printer before
- name: LexicalSyntacticFeaturizer
"features": [
["low", "title", "upper"],
["BOS", "EOS", "low", "upper", "title", "digit"],
["low", "title", "upper"],
]
- name: rasa_nlu_examples.meta.Printer
alias: printer after
- name: CountVectorsFeaturizer
analyzer: char_wb
min_ngram: 1
max_ngram: 4
- name: DIETClassifier
epochs: 1
policies:
- name: MemoizationPolicy
- name: KerasPolicy
- name: MappingPolicy
Example 2: With POS
language: en
pipeline:
- name: SpacyNLP
model: "en_core_web_sm"
- name: SpacyTokenizer
- name: rasa_nlu_examples.meta.Printer
alias: printer before
- name: LexicalSyntacticFeaturizer
"features": [
["low", "title", "upper", "pos"],
["BOS", "EOS", "low", "upper", "title", "digit", "pos"],
["low", "title", "upper", "pos"],
]
- name: rasa_nlu_examples.meta.Printer
alias: printer after
- name: CountVectorsFeaturizer
analyzer: char_wb
min_ngram: 1
max_ngram: 4
- name: DIETClassifier
epochs: 1
policies:
- name: MemoizationPolicy
- name: KerasPolicy
- name: MappingPolicy
Results
When you train these pipelines you can see that indeed it adds features to the pipeline.
Results without POS
printer before
text : yo
intent: {'name': None, 'confidence': 0.0}
entities: []
text_spacy_doc: yo
tokens: ['yo', '__CLS__']
printer after
text : yo
intent: {'name': None, 'confidence': 0.0}
entities: []
text_spacy_doc: yo
tokens: ['yo', '__CLS__']
text_sparse_features: <2x18 sparse matrix of type '<class 'numpy.float64'>'
with 12 stored elements in COOrdinate format>
Results with POS
printer before
text : yo
intent: {'name': None, 'confidence': 0.0}
entities: []
text_spacy_doc: yo
tokens: ['yo', '__CLS__']
printer after
text : yo
intent: {'name': None, 'confidence': 0.0}
entities: []
text_spacy_doc: yo
tokens: ['yo', '__CLS__']
text_sparse_features: <2x122 sparse matrix of type '<class 'numpy.float64'>'
with 14 stored elements in COOrdinate format>
You can see that the lexical feature with pos added really do add features. The sparse feature matrix is now large in shape but we’ve only added 1 non-zero component for each token (yo and __CLS__, the __CLS__ token represents the entire sentence). This implies that the POS features are added as sparse features to the pipeline.
 .
.